Software
Data-Intensive Distributed Computing (Fall 2018)
Bespin
Bespin is a software library that contains reference implementations of "big data" algorithms in MapReduce and Spark. It provides sample code for many of the algorithms we'll be discussing in class and also provides starting points for the assignments. You'll want to familiarize yourself with the library.
Single-Node Hadoop: Linux Student CS Environment
A single-node Hadoop cluster (also called "local" mode) comes
pre-configured in the linux.student.cs.uwaterloo.ca
environment. We will ensure that everything works correctly in this
environment.
TL;DR. Just set up your environment as follows (in bash; adapt accordingly for your shell of choice):
export PATH=/usr/lib/jvm/java-8-openjdk-amd64/jre/bin:/u3/cs451/packages/spark/bin:/u3/cs451/packages/hadoop/bin:/u3/cs451/packages/maven/bin:/u3/cs451/packages/scala/bin:$PATH export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
Note that we do not advise you to add the above lines to
your shell config file (e.g., .bash_profile), but rather
to set up your environment explicitly every time you log
in. The reason for this is to reduce the possibility of conflicts when
you start using the Datasci cluster (see below).
Details. For the course we need Java, Scala, Hadoop, Spark,
and Maven. Java is already available in the default user environment
(but we need to point to the right version). The rest of the packages
are installed in /u3/cs451/packages/. The
directories scala, hadoop, spark,
and maven are actually symlinks to specific
versions. This is so that we can transparently change the links to
point to different versions if necessary without affecting downstream
users. Currently, the versions are:
- Java: 1.8.0
- Scala: 2.11.8
- Hadoop: 3.0.3
- Spark: 2.3.1
- Maven: 3.3.9
Single-Node Hadoop: Personal Install
As an alternative of using the single-node Hadoop cluster
on linux.student.cs.uwaterloo.ca, you may wish to install
all necessary software packages locally on your own machine. We
provide basic installation instructions here, but the course staff
cannot provide technical support due to the size of the class and the
idiosyncrasies of individual systems. We will be responsible for
making sure everything works properly in the Linux Student CS
Environment (above), but if you want to install everything on your own
machine for convenience, you're on your own.
Both Hadoop and Spark work fine on Mac OS X and Linux, but may be difficult to get working on Windows. Note that to run Hadoop and Spark on your local machine comfortably, you'll need at least 4 GB memory and plenty of disk space (at least 10 GB).
You'll also need Java (JDK 1.8), Scala (use Scala 2.11), and Maven (any reasonably recent version).
The versions of the packages installed
on linux.student.cs.uwaterloo.ca are as follows:
Download the above packages, unpack the tarball, add their
respective bin/ directories to your path (and your shell
config), and you should be go to go.
Alternatively, you can also install the various packages using a
package manager, e.g., apt-get, MacPorts, etc. However,
make sure you get the right version.
Distributed Hadoop Cluster: Datasci
In addition to running "toy" Hadoop on a single node (which obviously defeats the point of a distributed framework), we're going to using the school's modest Hadoop teaching cluster called Datasci.
Accounts are already set up for students enrolled in the course. You should be able to log into the cluster as follows:
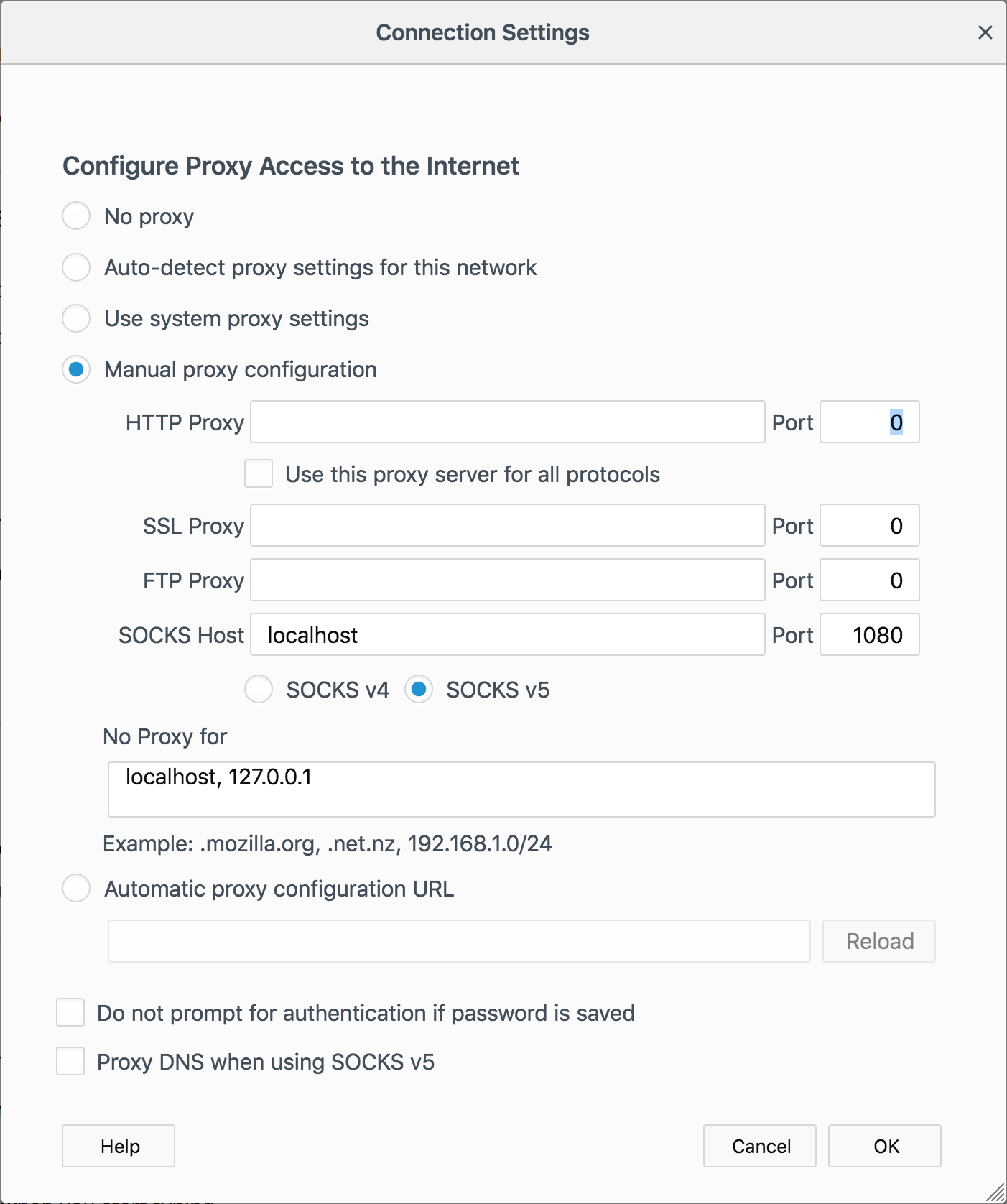
ssh -D 1080 datasci.cs.uwaterloo.ca
The -D option specifies dynamic port forwarding, which
you'll need for accessing the Hadoop UIs through a SOCKS proxy. The
simplest approach is via the Firefox browser: go to preferences and
access "Network Proxy" settings: your settings should look
something like this. You
should then be able to access the Resource Manager (RM) webapp
at http://datasci.datasci-domain.cs.uwaterloo.ca:8088/cluster.
It's important that you get the proxy working, because the RM webapp
is the primary point of access for examining and debugging jobs on the
cluster.
{kind=link}
With Firefox, the proxy setup limits your ability to access other sites; turn off the proxy once you're done with the cluster. One helpful tip while working on assignments is to access the cluster webapp in Firefox, and use another browser for accessing other sites. There are many other equivalent ways to set up your proxy (different OSes, different browsers, etc.) as well as alternative workflows. Feel free to share tips, experiences, etc. on Piazza.